在过去的1个月里,越来越多的人开始在 Mac 上运行本地 AI 大模型。比如使用 Ollama 来运行各种模型,再通过 OpenCat 或 Ollama桌面客户端 来调用。但很多人都有一个非常痛苦的体验:速度慢、推理卡顿、token 每秒只有个位数。
尤其是在 Mac Mini 或 16GB 内存设备 上,这个问题更明显。今天给大家介绍一个 Mac 本地跑模型的加速神器 —— OMLX。
它可以让本地模型 推理速度提升 10 倍以上,即使是 丐版 Mac Mini 也能轻松运行大模型。
下面我带大家 完整实测 + 部署教程
一、为什么 Mac 本地模型这么慢?
很多人在 Mac 上运行本地模型时,一般是这样的架构:
Ollama → 本地模型 → OpenCat / AI工具
但默认情况下:
- 推理效率不高
- KV Cache利用率低
- CPU/GPU 调度不充分
所以经常会出现这种情况:
- 回复 一个字一个字往外蹦
- 每秒 3~5 token
- 一个简单问题 几十秒甚至几分钟
这对于日常使用来说体验非常差。
二、OMLX:Mac 本地模型加速神器


OMLX 的核心作用:
- 优化本地模型推理
- 提升 token 生成速度
- 管理模型缓存
- 提供 OpenAI API 接口
- 支持压力测试
简单理解:
OMLX = Mac 本地 AI 模型加速服务器
部署后,本地模型速度通常可以 提升 5~10 倍以上。
三、Mac Mini 推荐模型
如果你的设备是 16GB Mac Mini,推荐使用:
Qwen3.5-9B :[点击前往] 进行下载
原因:
| 模型 | 大小 | 推荐设备 |
|---|---|---|
| Qwen3.5 4B | ~3GB | 8GB Mac |
| Qwen3.5 9B | ~6.6GB | 16GB Mac |
| Qwen3.5 27B | ~17GB | 32GB+ |
9B 模型在 性能和质量之间非常平衡。
四、安装 Ollama

首先安装 Ollama。
步骤:
打开官网下载安装
【点击前往】
安装完成后打开终端
下载 Qwen3.5 9B 模型
ollama run qwen2.5:9b
下载大小:约 6.6GB
下载完成后,就可以测试模型:
ollama run qwen2.5:9b
五、速度实测(未优化)
我们先测试一个简单的数学推理题:
2,6,12,20,30,(?)
规律是:
n(n+1)
第六个数:
6×7 = 42
但在 Ollama 默认推理下:
结果:
| 项目 | 时间 |
|---|---|
| 开始生成 | 20 秒 |
| 完整回答 | 1分50秒 |
速度非常慢。
六、安装 OMLX
在安装之前请确保你当前的mac上已经安装了Openclaw,没有安装的话可以通过下面的一键安装命令:
curl -fsSL https://openclaw.ai/install.sh | bash
来进行安装、升级到最新版本!

4、接下来安装 OMLX。
目前 Github 已经有 4000+ Star。
下载步骤:
打开项目 Release 页面
下载最新版本【点击前往】
注意选择正确版本:
| 文件 | 适合设备 |
|---|---|
| square 版本 | 老 Mac |
| tar 版本 | M5 / 最新 macOS |
下载后直接拖入 Applications 安装。
七、启动 OMLX 服务器
打开 OMLX 后:
配置如下
默认端口:8000
API Key:随便设置,例如:12345678
点击:
Start Server
当看到 绿色状态 就说明启动成功。
进入后台:
http://127.0.0.1:8000
八、配置模型缓存(非常关键)
在设置里建议这样配置:
内存限制
如果是 16GB Mac
12GB
热缓存
8GB
冷缓存(强烈建议)
例如:
100GB
作用:
- 保存 KV cache
- 模型下次启动更快
九、下载模型
OMLX 不识别 Ollama 模型格式。
所以需要 重新下载模型。
在后台:
Downloader
搜索:
Qwen3.5 9B
直接下载即可。

十、对接 OpenCat
接下来把 OMLX 接入 OpenCat。
终端运行:
opencat config
配置:
Provider
Custom Provider
API 地址
http://127.0.0.1:8000/v1
API Key
留空即可。
然后填写模型 ID:
模型ID的获取地址:http://127.0.0.1:8000/v1/models
复制其中的模型 ID。
配置完成后即可。
十一、速度再次实测
同样的问题:
2,6,12,20,30,(?)
结果:
| 方案 | 用时 |
|---|---|
| Ollama 原生 | 1分50秒 |
| OMLX 加速 | 10~15秒 |
速度提升接近 10 倍!
几乎可以做到 秒级响应。
十二、OMLX 的高级功能
OMLX 还有很多强大功能:
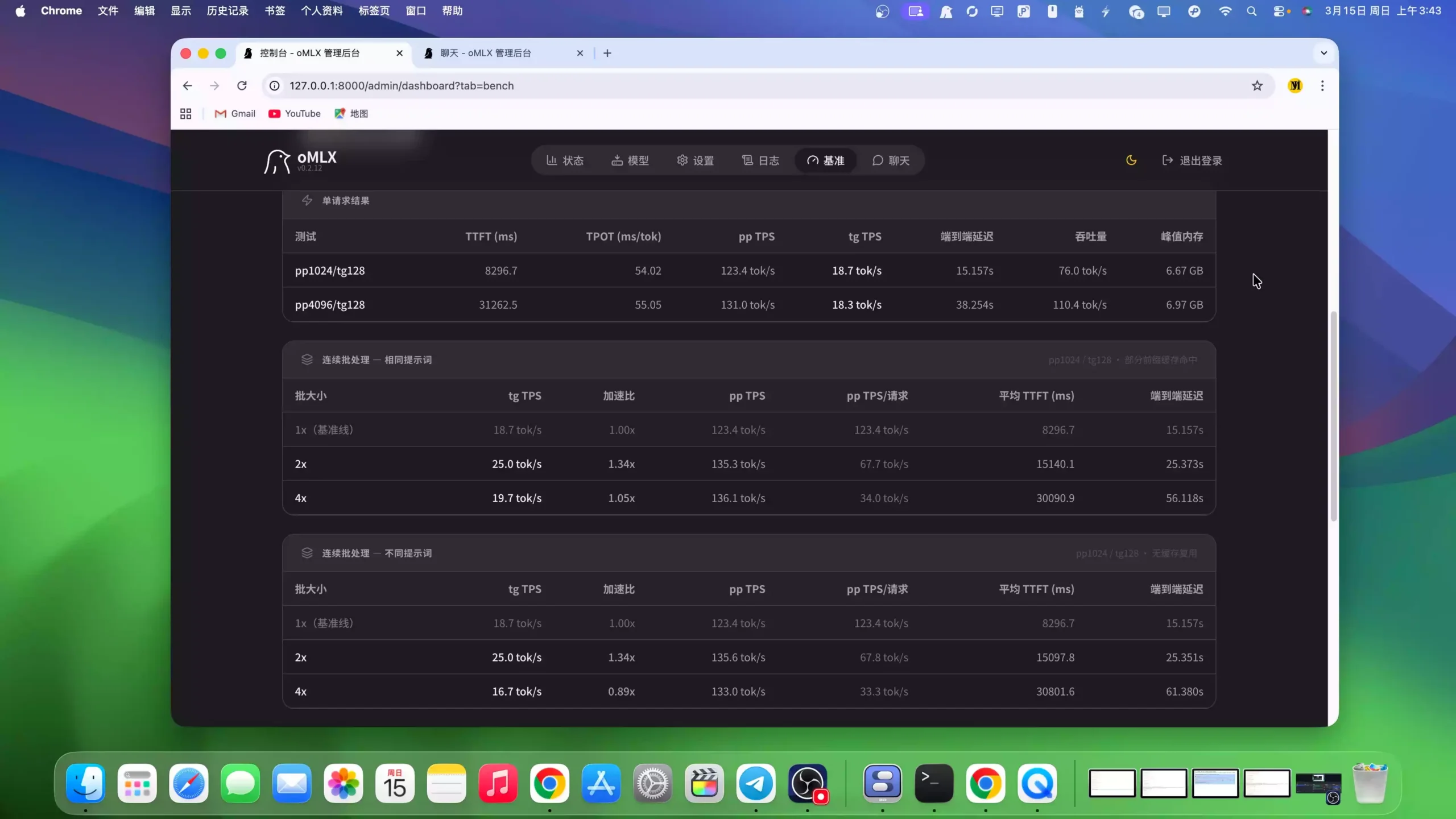
性能矩阵测试
可以测试:
- 单线程
- 多线程
- 并发压力
评估:
每秒 token 数量
OpenAI API 兼容
支持:
- OpenAI API
- Cloud 模型
- 自定义模型
可以直接当:
本地 OpenAI API Server
KV Cache 持久化
大幅提升:
- 模型启动速度
- 上下文推理效率
如果你想在 Mac 上本地跑 AI 大模型,那么这套组合非常推荐:
Ollama
+
Qwen3.5
+
OMLX
+
OpenCat
优势:
- 本地运行
- 不消耗 token
- 推理速度大幅提升
- Mac Mini 也能轻松运行
尤其是对于喜欢折腾 本地 AI + 自动化工具 的朋友来说,这套方案真的非常香。